Looking for Even More Performance
03 Jun 2014Anyone who has looked around the asynchronous driver’s website should quickly realize that we take performance seriously, very seriously. We spend countless hours looking for ways to shave another millisecond of latency here or avoid contention over there.
If we are honest with ourselves though we will admit that the really big performance wins are not from the fine tuning we have done but instead for the architectural decisions. Most of the drivers real performance comes from the core of the driver’s API being asynchronous. This allows us to make sure that we can keep the connections full of requests to keep the thread MongoDB creates to handle the connection as busy as possible. There is no black magic here. We are just allowing the driver to get out of its own way in addition to get out of your application’s way too. All of the other tuning is just making sure we don’t give those fundamental gains away.
With the 2.0.0 release of the driver we take a step closer to having a core that will scale from systems pushing thousands of requests a second all the way down to embedded devices that are resource constrained. I will talk about those small or micro deployments in a future post but today I want to take a hard look at the large scale, high performance deployments.
Any system pushing the performance envelope will use the standard sharded cluster of replica sets. Each replica set provides the high availability and the sharding provides the ability to scale out. So where can we get the next big performance win?
If you look at my incredibly crude drawing of our deployment structure below you will immediately notice that all of the requests have to travel through the mongos process. No big surprise there right. That is how it is supposed to work. I’ll agree that for MongoDB that is how it is supposed to work. But does it have to work that way?
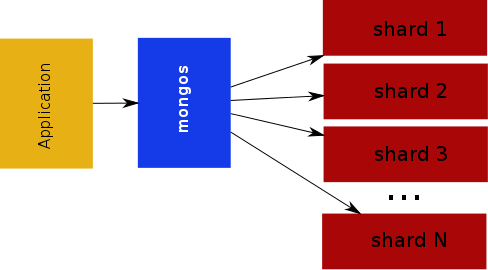
There are many examples of No-SQL databases that do not use a router process within the cluster. Instead they expect the client driver to maintain the logic for what data lives where and route the requests itself. It is easy to guess why MongoDB Inc. would not want to use that strategy. The logic for the mongos is not easy and maintaining and updating that logic within all of the different drivers would slow the speed with which they can innovate. All very logical and maybe using the mongos does not cause a performance problem?
Afraid is does but only for drivers that can send additional request on a socket before getting the reply. In other words asynchronous drivers. (I should note that all of the drivers supported by MongoDB Inc. do not have this capability.)
To understand why I present another series of pictures.
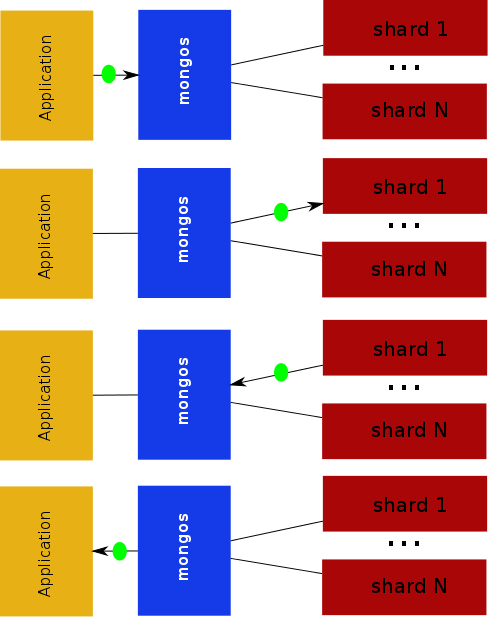
In this first picture time progresses down the picture and we see the travels of a single request as it is sent from the application through the mongos and finally to the shard to be processed and the response to make the return trip back to the mongos and finally back to the application. For this, one at a time, scenario the overhead of the mongos is negligible:
- The processing logic the mongos performed is absolutely required so there is no overhead there.
- You could argue that the serialization and de-serialization of the BSON messages causes a problem but the reality is BSON was designed to be very lightweight to parse and process for C++ applications (like the mongos).
- That just leaves the overhead for the extra network hop. This is mitigated by the common (and recommended) deployment strategy of putting the mongos on the same host as the application. That will make the application to mongos network connection very high bandwidth and also very low latency.
Looks good. Now lets draw the same event with an asynchronous driver.
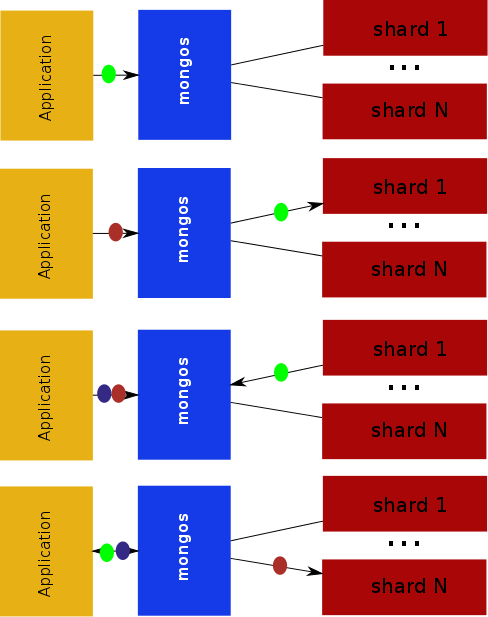
Not so nice. The story starts the same. Our green request makes it to the mongos and is sent to the shard but while the mongos was processing that request we see the application has already sent another one and it is stuck waiting. The shard finishes processing that first green request and sends the reply to the mongos but look; now there are two requests waiting! Finally the mongos receives the green reply and forwards it back to the application and finally processes the second request but our third request is still waiting, and waiting.
The worst part is there is nothing the driver can do to speed up the processing. No matter how asynchronous and high performance we make our applications and driver we will always be waiting on the synchronous processing of the mongos.
That leaves us with two options:
- Rewrite the mongos to be asynchronous.
- Stop using the mongos to route requests.
As writers of a Java driver we don’t have the expertise to rewrite the C++ mongos. We do have the expertise to implement (some) of its functionality in Java.
In our next post we will look in more detail what functions we need to emulate from the mongos.